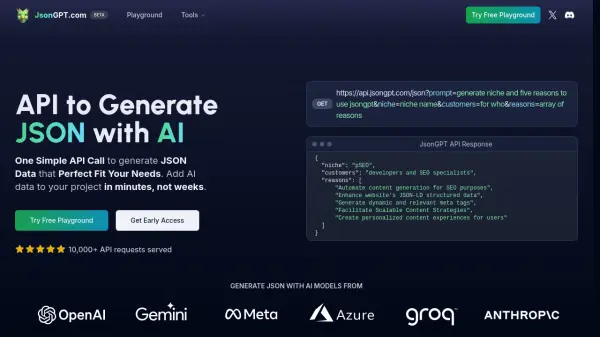
Rubii: AI Character Community
Rubii: AI Character Community

What is LLM Outputs?
LLM Outputs provides a solution for maintaining the accuracy and reliability of structured data generated by Large Language Models (LLMs). It specializes in detecting and correcting inaccuracies, format errors, and contextual inconsistencies within datasets like JSON, CSV, and XML. By validating data against user-defined formats and associated context, the platform helps prevent AI-generated hallucinations that could compromise data integrity and impact downstream processes.
The tool offers seamless integration into existing systems through code snippets, allowing for real-time validation and monitoring. This ensures that structured data outputs conform to required specifications and align with their intended use, thereby preventing issues in areas like AI training data, financial datasets, and enterprise data pipelines. Its focus on low-latency performance enables quick detection and correction, maintaining operational efficiency.
Features
- Superior Hallucination Detection Models: AI models designed to detect and eliminate hallucinations in structured data.
- Effortless Integration: Developer-friendly integration with existing systems via code snippets.
- Low Latency for Real-Time Corrections: Detect and correct issues in structured data in real-time.
- Format Conformance: Ensures structured data adheres to required specifications (JSON, CSV, XML, etc.).
- Contextual Accuracy Maintenance: Guarantees data aligns with its intended use and context.
- Real-time Monitoring & Alerts: Tracks accuracy of structured data outputs and provides alerts for discrepancies.
Use Cases
- Ensure AI-generated reports and outputs contain only accurate, reliable data (AI Data Integrity).
- Prevent errors in financial datasets that could lead to misinformed decisions (Financial Data Validation).
- Validate large-scale data streams for enterprise applications to avoid costly errors (Enterprise Data Pipelines).
- Ensure accurate data is fed into AI models to enhance training results (AI Training Data).
FAQs
-
What is hallucination in structured data, and why is it important to detect it?
LLM Outputs defines hallucination in structured data as errors or inconsistencies generated by AI models. Detecting it is crucial for ensuring the accuracy and integrity of data like JSON or CSV, making AI operations more reliable and efficient by validating against predefined schemas. -
How does LLM Outputs check structured data for accuracy?
LLM Outputs checks structured data against predefined schemas and rules to ensure it is structurally and contextually accurate and free from errors. It flags discrepancies for corrective action before the data is used. -
What types of structured data does LLM Outputs support?
LLM Outputs supports various common structured data formats used in AI and data operations, including JSON and CSV, and is designed to be flexible for specific data environment needs. -
Can LLM Outputs be integrated into an existing data pipeline?
Yes, LLM Outputs can be integrated into existing data pipelines to work alongside current tools, validating and cleaning structured data before it proceeds to the next stage. -
How does the platform handle real-time systems?
LLM Outputs utilizes low-latency APIs, allowing for the detection and correction of issues in structured data in real-time to ensure operations are not interrupted.
Related Queries
Helpful for people in the following professions

Featured Tools
Join Our Newsletter
Stay updated with the latest AI tools, news, and offers by subscribing to our weekly newsletter.