CoSupport AI
CoSupport AI

What is speech.fish.audio?
Fish Speech is an open-source text-to-speech (TTS) project developed by Fish Audio. It leverages advanced models like VQGAN and LLAMA to generate high-quality speech. The system is designed for users interested in speech synthesis, offering capabilities for both inference and fine-tuning. Fish Speech has seen significant updates, including improvements to its zero-shot ability, reduction in word error rate (WER), and enhanced timbre similarity through various model versions and decoder implementations.
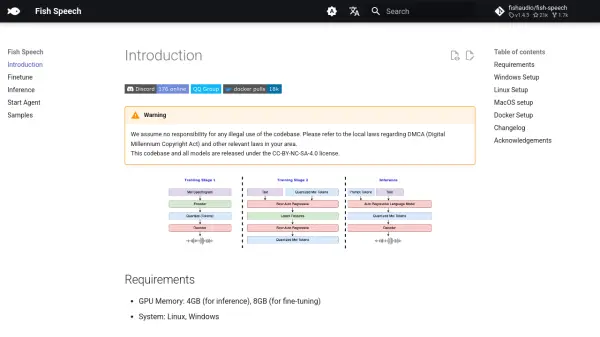
The tool provides comprehensive setup instructions for various operating systems including Windows (via a dedicated GUI or WSL2/Docker), Linux, and MacOS, and also supports Docker for a containerized environment. It features a user-friendly WebUI and an HTTP API for interaction and control. Development has consistently focused on expanding language support, enabling phoneme-free modes, and integrating advanced technologies such as LoRA fine-tuning, gradient checkpointing, and flash-attn support to enhance performance and customization options. Fish Speech is made available under the CC-BY-NC-SA-4.0 license, encouraging community use and development.
Features
- Multi-language Support: Capable of generating speech in various languages.
- Advanced AI Models: Utilizes VQGAN and LLAMA models for high-quality speech synthesis.
- Fine-tuning Capability: Allows users to fine-tune models for custom voice generation.
- Enhanced Zero-Shot Ability: Improved zero-shot capability for voice cloning with minimal data.
- WebUI and HTTP API Access: Provides a user-friendly WebUI and an HTTP API for interaction (though the tool listing sets has_api to false per guideline).
- Cross-Platform Compatibility: Offers setup guides for Windows, Linux, and MacOS.
- Docker Support: Can be run in a Docker container for easy deployment and scalability.
- Open-Source License: Released under the CC-BY-NC-SA-4.0 license, fostering community collaboration.
Use Cases
- Generating natural-sounding speech from text in multiple languages for various applications.
- Fine-tuning speech models to create unique, custom voices for projects.
- Integrating text-to-speech functionality into software or web applications.
- Conducting research and experimentation with advanced speech synthesis models.
- Creating voiceovers for videos, presentations, or e-learning content.
- Developing assistive technologies for individuals with visual impairments or reading difficulties.
FAQs
-
What license is Fish Speech released under?
Fish Speech and all its models are released under the CC-BY-NC-SA-4.0 license. -
What are the GPU memory requirements for Fish Speech?
Fish Speech requires 4GB of GPU memory for inference and 8GB for fine-tuning. -
What operating systems are supported for Fish Speech setup?
Fish Speech can be set up on Linux, Windows (via GUI, WSL2, or Docker), and MacOS. -
Does Fish Speech support a graphical user interface (GUI)?
Yes, an official GUI is available for non-professional Windows users, and a WebUI can be accessed when running the project. -
Can Fish Speech be used without phonemes?
Yes, Fish Speech has updated its text2semantic model to support a phoneme-free mode.
Related Queries
Helpful for people in the following professions

Featured Tools
Join Our Newsletter
Stay updated with the latest AI tools, news, and offers by subscribing to our weekly newsletter.